🎶Code in this post can be found at the jupyter notebook in my “saeExploration” repo.
Find features that reflect positive emotions
To find the features related to a specific emotion, I write five sentences containing the key words for each emotion. For example, for happy emotions I have:
I choose to look for features that reflect happiness and sadness. Apart from that, I also wonder if the feature that reflects excitedness has something to do with the one that reflects happiness (they are alike from the semantic level at least.)
For a start, I inspected the residual stream in layer_7. The SAE we choose is gpt2-small-res-jb which hooks at the residual stream at the entrance of a layer. The prompts were fed into the model and the outputs were SAE activations. I checked the activations at the word “happy” for all the prompts and calculated the mean value of them. I visualized them as below:
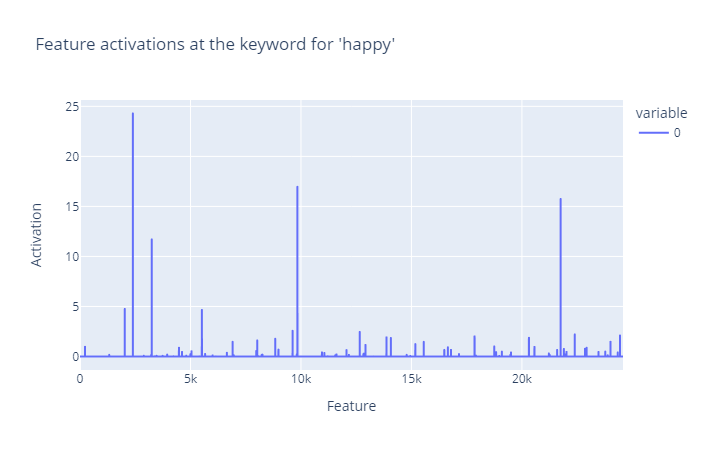 Figure 1: Feature activations at the keywords for happy emotion
Figure 1: Feature activations at the keywords for happy emotionObviously there are three SAE features that activate most actively on the happy emotion, and their feature ids are 2392, 9840 and 21753. I checked the feature 2392 in Neuronpedia and got its feature dashboard:
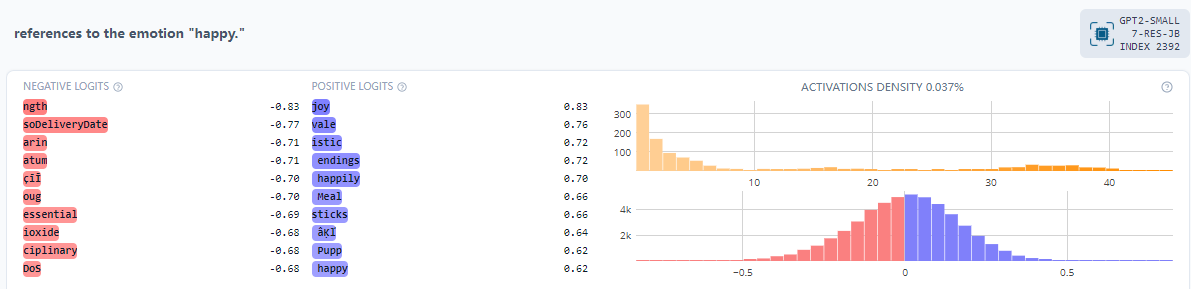 Figure 2: SAE feature 2393 on the dashboard (https://neuronpedia.org/gpt2-small/7-res-jb/2392?embed=true&embedexplanation=true&embedplots=true&embedtest=true&height=300).
Figure 2: SAE feature 2393 on the dashboard (https://neuronpedia.org/gpt2-small/7-res-jb/2392?embed=true&embedexplanation=true&embedplots=true&embedtest=true&height=300).Later I found features for sadness and excitedness in the same way. The top-3 features activating for “sad” and “excited” are [2045, 23774, 10866] and [8935, 9840, 3247] respectively.
Compare the features related to happiness and excitedness
I want to see the difference between “happy features” and “excited features” since they are both positive emotions. So I compared their top-3 features and only kept the features that activate on both “happy” and “excited”. They are visualized as below:
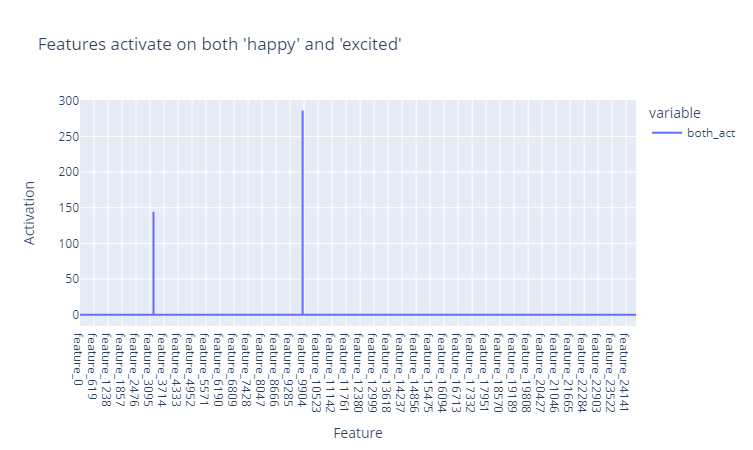 Figure 3: Feature activations on both happy and excited emotions at the residual pre stream in layer_7.
Figure 3: Feature activations on both happy and excited emotions at the residual pre stream in layer_7.From the figure above, we can easily find out the two features shared by happiness and excitedness. It seems that these two features contain positive emotion concepts, which means they are close to each other on the semantic level.
A deeper investigation into the features related to happiness
From the previous result, we can see that there are 3 features that fire quite actively on happiness. Since they share similar semantic meanings, I guess that the representations of features activating on the same emotion (i.e. 2392, 9840 and 21753) have high similarities. To prove this, I try to inspect the representation of one prompt which expresses happiness and calculate the cosine similarities among representations of different features. Here the representations of different layers are calculated as below: $$ feat \_ repr = W_{dec} * SAE \_ activations $$ Note that the * operation is a dot product. The W_dec in the formula above is the decoder matrix of SAE with a shape of (d_sae, d_model). We know that according to the definition of dictionary learning, each vector in the dimension of d_sae corresponds to a base vector for an SAE feature. Each element in the SAE_activations can be seen as the intensity of the feature at that position. So by multiplying W_dec and SAE_activations we can get a representation of shape $ (d \_ model,) $ which expresses the features in the vector space of SAE that is sparser and more interpretable than that of the original model.
To visualize the similarities among features, I choose to use the heatmap. Note that in order to make it clear, I mainly focus on features 2392, 9840 and 21753 and using negative sampling to get some other features for comparison. I randomly pick 6 features except for the three features mentioned above. The similarities are calculated and shown as below:
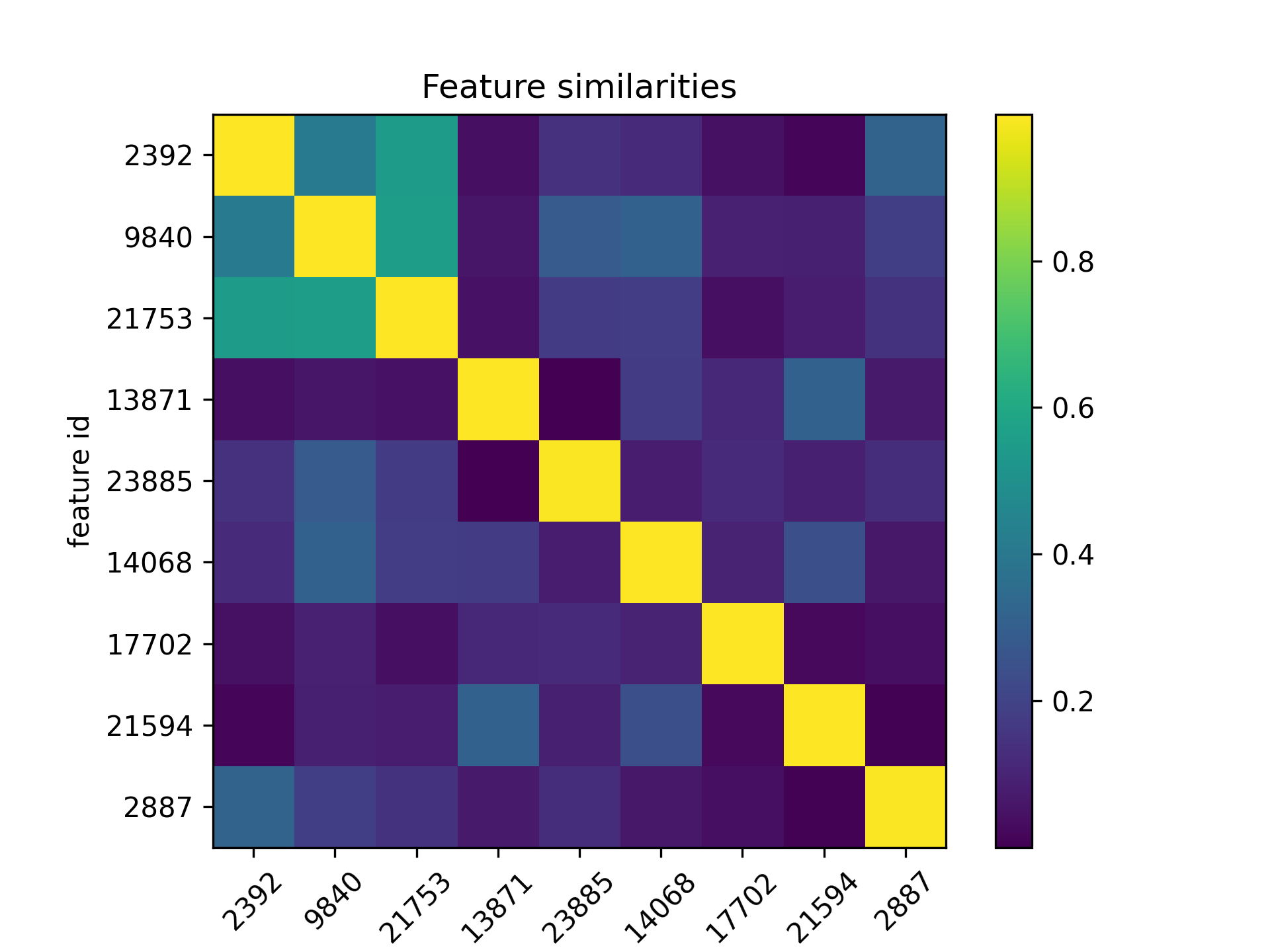 Figure 4: Feature similarities on the word “happy” at the residual pre stream in layer_7.
Figure 4: Feature similarities on the word “happy” at the residual pre stream in layer_7.Obviously we can find that the three features that fire most actively on “happy” are more similar to each other (the top left 3*3 square), thus my hypothesis is proved intuitively.
Features in different layers
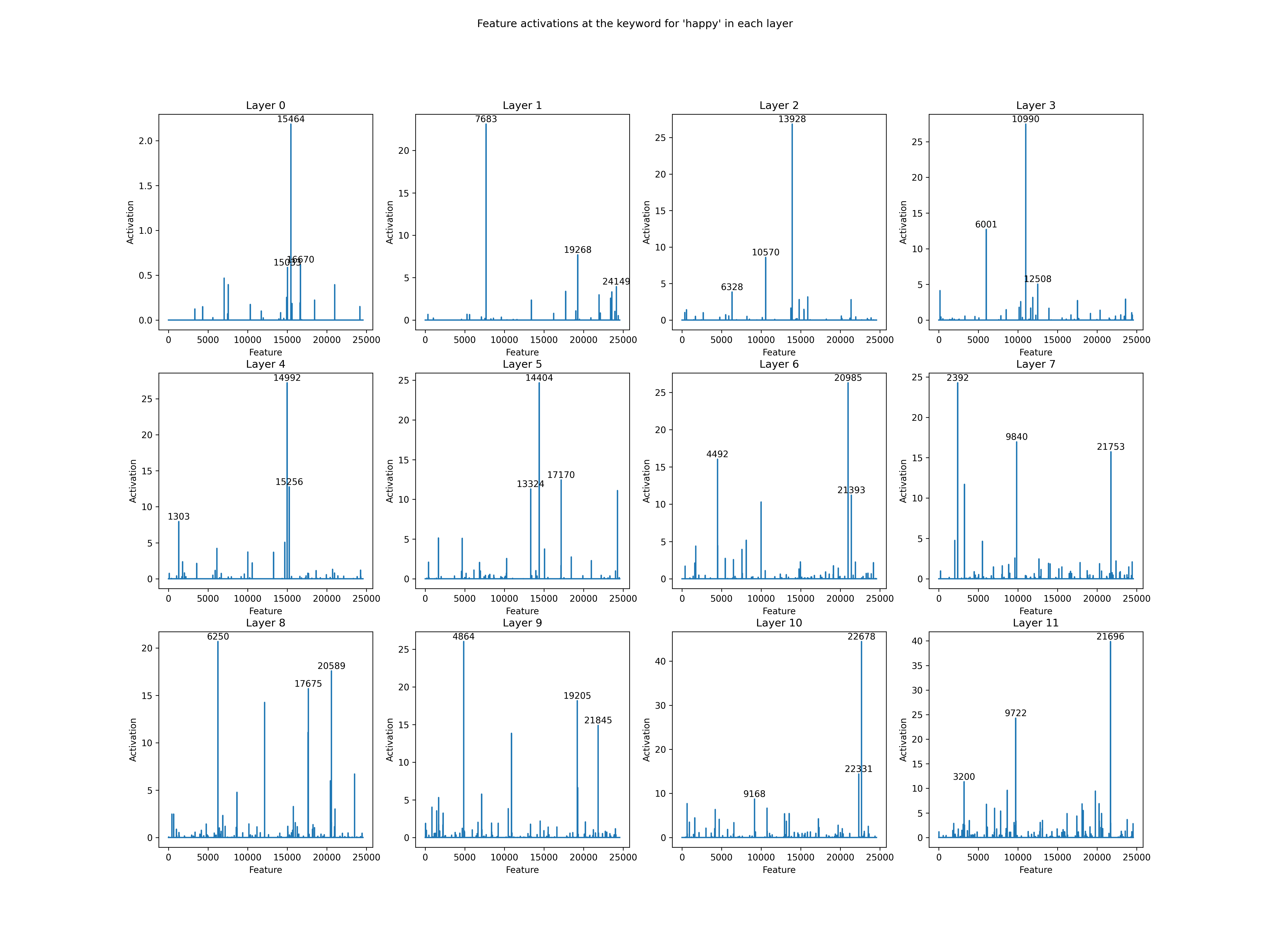 Figure 5: Feature activations on the word “happy” at the residual pre stream in 12 layers.
Figure 5: Feature activations on the word “happy” at the residual pre stream in 12 layers.Previously I inspected in the 8th layer of gpt2-small and found some emotional features. Now I want to know if similar features exist in other layers, and how they are related to each other. I inspect the autoencoder features in each layer and observe their activations on the word “happy”. The result is shown in Fig 5. We can find that: * Eachlayer has more than 3 features that activate on the happy emotion. * Thepositions of activating features are different from those in other layers.
Though the positions of activating features are different, I guess it’s just the problem of feature orders. For example, the feature 7683 in layer_1 may be the same kind or even exactly the same feature as feature 13928 in layer_3, though the positions are different. In order to prove this, I choose to visualize the feature representations of SAE outputs. The result is shown below:
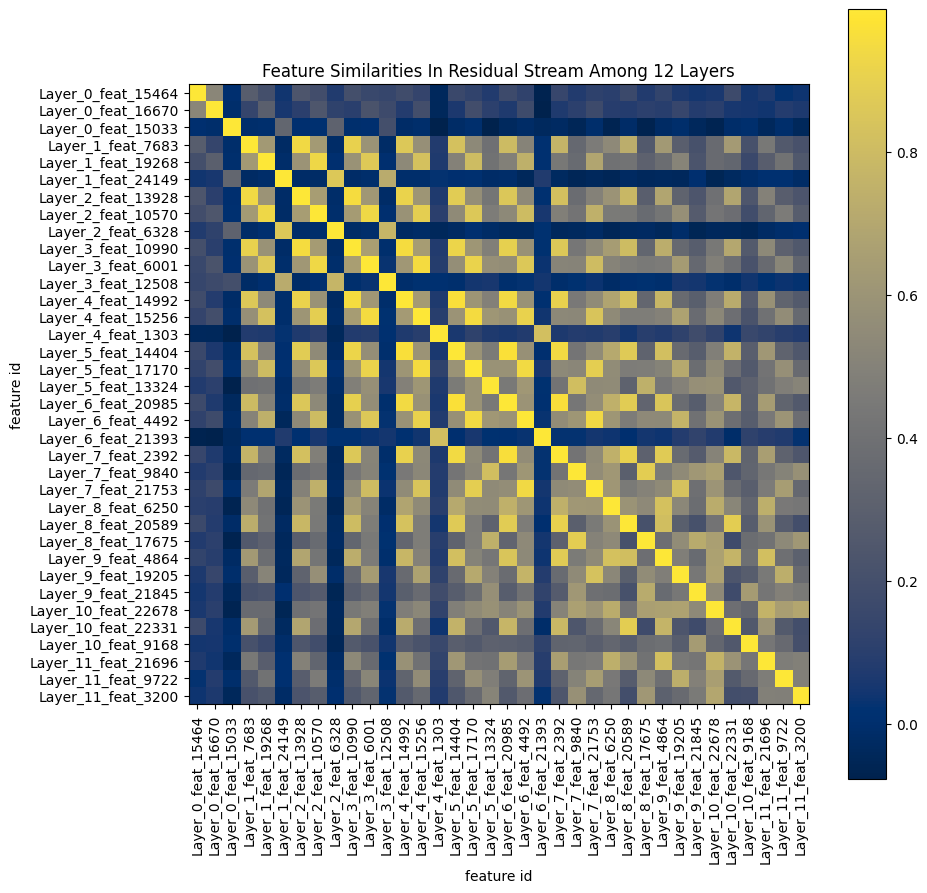 Figure 6: Feature similarities on the word “happy” at the residual pre stream in 12 layers.
Figure 6: Feature similarities on the word “happy” at the residual pre stream in 12 layers.From the figure above, I got some interesting points about the feature distribution:
- The features in the first layer have lower similarities with those in later layers. I guess this is because the first layer gets limited information from previous layers, so it cannot express relatively complicated concepts like emotions. I think maybe the first layer contains some low level concepts that are not shown in this figure, which I will explore in the future.
- Afeature in a layer often corresponds to a feature in another layer. For example, feature 7683 in layer_1 corresponds to feature 13928 in layer_2, which has a similarity of 0.939. This means they are related to each other across different layers, sharing similar semantic meanings.
- Afeature in a layer tends to be more alike to features in nearby layers. For example, feature 7683 in layer_1 is more similar to feature 13928 in layer_2 than feature 2392 in layer_7, with a similarity of 0.939 to 0.825. I think it’s because the vector spaces of nearby layers are relatively close to each other. When two layers are far from each other, the difference between their vector spaces is significant due to a lot of linear and nonlinear manipulations between layers. Thus the features would share low similarities regardless of similar semantic meanings.